使用Python分析处理数据并用pyecharts进行可视化 |
您所在的位置:网站首页 › pycharm pyecharts › 使用Python分析处理数据并用pyecharts进行可视化 |
使用Python分析处理数据并用pyecharts进行可视化
|
使用Python分析处理数据并用pyecharts进行可视化
一、数据文件二、使用pyecharts进行可视化1.各岗位占比饼图2.各岗位平均起薪柱状图3.各城市招聘量柱状图及平均薪资折线图组合4.各城市岗位薪资分布热力图5.数据科学工具要求排行柱状图和岗位技能要求词云6.不同岗位对学历和工作经验要求分布柱状图7.将以上所有图组合在一个页面中,并做出选项卡
补充以及GitHub链接
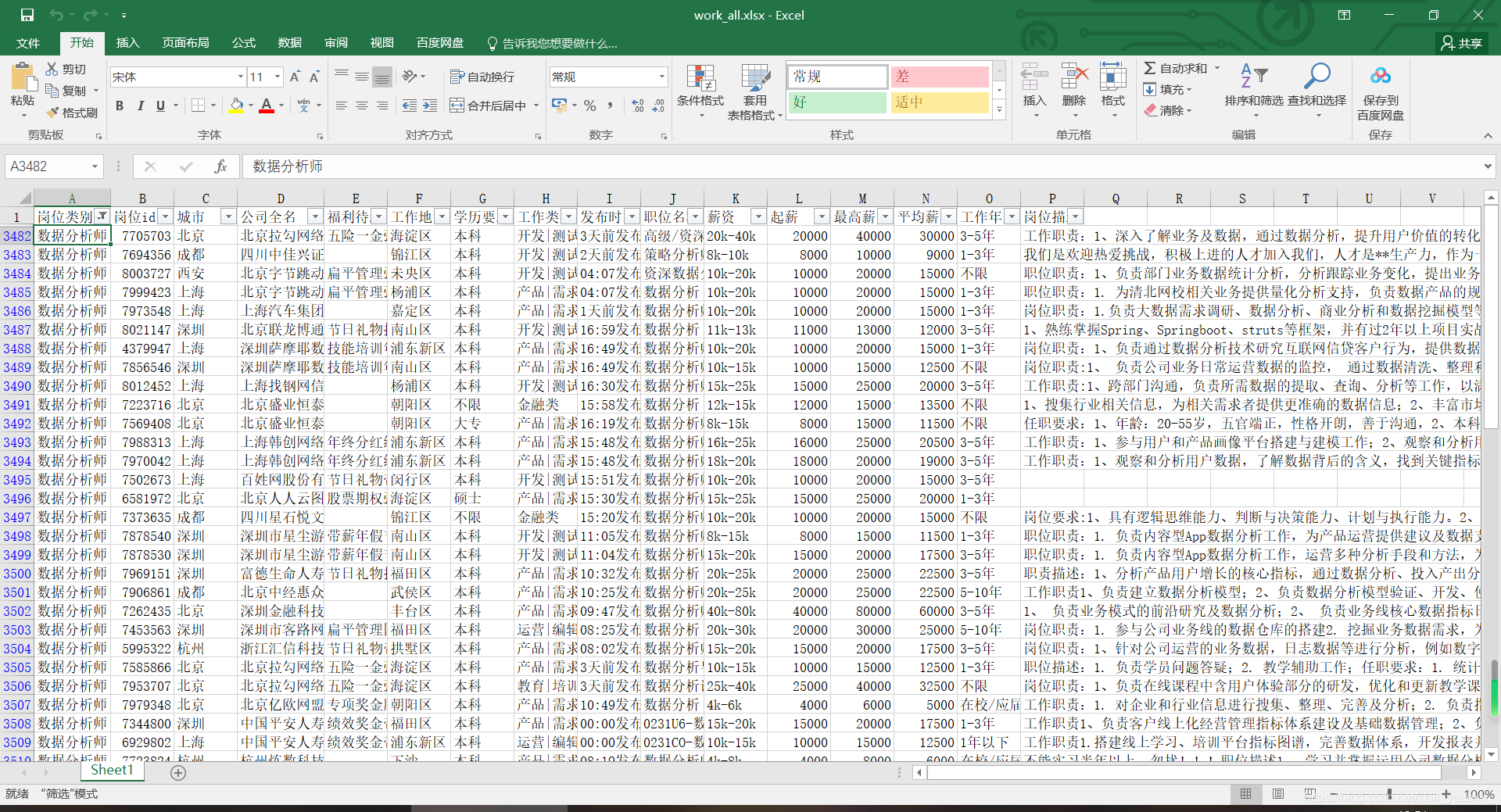
一、数据文件
包括各种岗位类别、城市、薪资水平、岗位要求等信息。 work_all.xlsx 进行可视化参考的网站: pyechart 各种图的示例: pyecharts-gallery 封装函数进行: 1.数据的读取和处理(每个绘图中均会用到) 2.提取词频排行前100的词(只在p5.py绘制词云中用到) publicFunction.py import pandas as pd import re import collections import jieba # 封装函数读取处理数据 def read_works(): # 1.处理数据 # 读取数据 data = pd.read_excel('work_all.xlsx') # 为了不影响原数据,所以拷贝一份 data_cy = data.copy() # 提取指定岗位的数据 # 注意:岗位类别需要处理空字符问题,岗位类别后都有一个空格,要去除空格才能读出来 # 去除空格 A = data_cy['岗位类别'].str.strip() # 把去除空格后的数据更改到原数据中 data_cy['岗位类别'] = A ''' 把属于数据运营、机器学习、数据科学、数据分析师、数据产品经理、商业数据分析的数据筛选出来, 并把其'岗位类别'列中的值全部替换为'数据科学'。 ''' # 把属于这些类别的提取出来放到B中 B = A.isin(['数据运营', '机器学习', '数据科学', '数据分析师', '数据产品经理', '商业数据分析']) # 把这些岗位的类别都替换为数据科学 data_cy.loc[B, '岗位类别'] = '数据科学' # 返回处理好的数据 return data_cy # 提取词频排行前100的词,此函数只在p5中的词云绘制中用到 def word_count(string_data): # 文本预处理,去除各种标点符号,不然统计词频时会统计进去 # 定义正则表达式匹配模式,其中的|代表或 pattern = re.compile(u'\t|\n| |;|\.|。|:|:\.|-|:|\d|;|、|,|\)|\(|\?|"') # 将符合模式的字符去除,re.sub代表替换,把符合pattern的替换为空 string_data = re.sub(pattern, '', string_data) # 文本分词 seg_list_exact = jieba.cut(string_data, cut_all=False) # 精确模式分词 # object_list = list(seg_list_exact) # list()函数可以把可迭代对象转为列表 # 运用过滤词表优化掉常用词,比如“的”这些词,不然统计词频时会统计进去 object_list = [] # 读取过滤词表 with open('./remove_words.txt', 'r', encoding="utf-8") as fp: remove_words = fp.read().split() # 循环读出每个分词 for word in seg_list_exact: # 看每个分词是否在常用词表中或结果是否为空或\xa0不间断空白符,如果不是再追加 if word not in remove_words and word != ' ' and word != '\xa0': object_list.append(word) # 分词追加到列表 # 进行词频统计,使用pyecharts生成词云 # 词频统计 word_counts = collections.Counter(object_list) # 对分词做词频统计 word_counts_top = word_counts.most_common(100) # 获取前100最高频的词 return word_counts_top 1.各岗位占比饼图p1.py import numpy as np from pyecharts.charts import Pie from pyecharts import options as opts ''' 1. 各岗位占比饼图 ''' # 1 读取数据 # 从publicFunction中导入read_works函数 from publicFunction import read_works # 调用此函数,完成数据的读取和处理 data_cy = read_works() # 2 统计不同岗位数量 # 按照岗位类别分组来统计,根据岗位id来计数 work_count = data_cy.groupby('岗位类别').count()['岗位id'] #print(work_count) # 3 计算岗位占比 # 算出work_count/work_count.sum())*100算出百分比,np.round( ,2)保留小数点后两位 work_ratio = np.round((work_count/work_count.sum())*100,2) # print(work_ratio) # 去pyecharts网站找到饼图模板 # https://pyecharts.org/#/zh-cn/basic_charts?id=pie%ef%bc%9a%e9%a5%bc%e5%9b%be # 要求的系列数据项,格式为 [(key1, value1), (key2, value2)],所以要进行数据的组合 # 组合数据 # # work_ratio.index.tolist()即岗位类别的名称 # print(work_ratio.index.tolist()) # *zip进行数据的组合压缩,再和占比放到一个列表中 work_name_ratio = [*zip(work_ratio.index.tolist(),work_ratio)] # print(work_name_ratio) # [('java', 5.94), ('python', 6.75), ('产品助理', 6.57), ('人事', 6.66), ...] # 4 绘图 # 实例化对象 p1obj = Pie() # 放入组合数据 # radius为饼图的半径,数组的第一项是内半径,第二项是外半径 p1obj.add('',work_name_ratio,radius=["40%", "75%"],) # 去pyecharts全局配置项中查参数 # https://pyecharts.org/#/zh-cn/global_options?id=legendopts%ef%bc%9a%e5%9b%be%e4%be%8b%e9%85%8d%e7%bd%ae%e9%a1%b9 p1obj.set_global_opts( # 标题 title_opts=opts.TitleOpts(title="各岗位占比"), # orient图例列表的布局朝向为竖着,离上方15%,离左边2% legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%") ) # b代表给的数据中的key,c代表给的数据中value,c的后面加百分号 p1obj.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}%")) # 当这个程序有可能被导入时,写这个判断 # 直接用python程序调用当前这个脚本时,__name__为__main__,执行下面 # 当这个程序被导入时,__name__不为__main__,便不会执行 if __name__ == '__main__': # # 生成页面 p1obj.render('1.各岗位占比饼图.html')生成网页 1.各岗位占比饼图.html p2.py import numpy as np from pyecharts.charts import Bar from pyecharts import options as opts ''' 2. 各岗位平均起薪柱状图 ''' # 1 读取数据 # 从publicFunction中导入read_works函数 from publicFunction import read_works # 调用此函数,完成数据的读取和处理 data_cy = read_works() # 2 计算各工作类别最低平均薪资 # 按照岗位类别分组来统计,根据起薪来计算平均值 work_salary = np.round(data_cy.groupby('岗位类别').mean()['起薪']) # print(work_salary) # 3. 绘图 # 去pyecharts-gallery网站找到模板示例 # https://gallery.pyecharts.org/#/Bar/bar_stack0 # 复制出来代码进行修改 # 实例化对象 p2obj = Bar() # 将职位转化为列表形式作为x轴 p2obj.add_xaxis(work_salary.index.tolist()) # print(work_salary.index.tolist()) # 将最低平均薪资转化为列表形式作为y轴 p2obj.add_yaxis("各平均起薪", work_salary.tolist(),category_gap="50%") # print(work_salary.tolist()) # 去pyecharts全局配置项中查参数 p2obj.set_global_opts( title_opts=opts.TitleOpts(title="不同岗位平均起薪"), # 让列的名字倾斜15度,负责有的名字太长,显示不出来 xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)) ) # 当这个程序有可能被导入时,写这个判断 # 直接用python程序调用当前这个脚本时,__name__为__main__,执行下面 # 当这个程序被导入时,__name__不为__main__,便不会执行 if __name__ == '__main__': # 生成页面 p2obj.render('2.各岗位平均起薪柱状图.html')生成网页 2.各岗位平均起薪柱状图.html p3.py import pandas as pd import numpy as np from pyecharts.charts import Bar,Line from pyecharts import options as opts ''' 3.各城市招聘量柱状图及平均薪资折线图组合 ''' # 1 读取数据 # 从publicFunction中导入read_works函数 from publicFunction import read_works # 调用此函数,完成数据的读取和处理 data_cy = read_works() # 只拿出数据科学的岗位进行分析 data_cy = data_cy[data_cy['岗位类别'] == '数据科学'].copy() # 2 统计城市招聘数据 # 按照城市分组来统计数量,根据岗位id来计数,进行降序排列 city_nums = data_cy.groupby('城市').count()['岗位id'].sort_values(ascending=False) # print(city_nums) # 要将城市对应的招聘量(用柱状图)和平均薪资(用折线图)放在一起展示 # 3 计算对应城市的平均薪资(按起薪资计算平均值) # 按照城市分组来统计数量,根据起薪来计算平均值 data_city = np.round(data_cy.groupby('城市').mean()['起薪']) # print(data_cy.groupby('城市').mean()) # 取招聘量前10个的城市的平均起薪 city_salary = data_city.loc[city_nums[:10].index.tolist()] # print(city_salary) # 4 绘图,要将城市对应的招聘量(用柱状图)和平均薪资(用折线图)放在一起展示 # 根据pyecharts-gallery中的示例来改 # https://gallery.pyecharts.org/#/Bar/multiple_y_axes p3obj = ( # 城市对应的招聘量的柱状图 Bar() # 取招聘量前10的城市 .add_xaxis(xaxis_data=city_nums[:10].index.tolist()) .add_yaxis( series_name="招聘量", yaxis_data=city_nums[:10].tolist(), label_opts=opts.LabelOpts(is_show=False), ) .extend_axis( yaxis=opts.AxisOpts( name="薪资", type_="value", # 薪资y坐标最低10000,最高20000 min_=10000, max_=20000, # interval=500, axislabel_opts=opts.LabelOpts(formatter="{value}"), ) ) # 去pyecharts全局配置项中查参数 .set_global_opts( title_opts=opts.TitleOpts(title="招聘与薪资排行榜"), tooltip_opts=opts.TooltipOpts( is_show=True, trigger="axis", axis_pointer_type="cross" ), xaxis_opts=opts.AxisOpts( type_="category", axispointer_opts=opts.AxisPointerOpts(is_show=True, type_="shadow"), ), # 招聘数量y坐标最低0,最高1500 yaxis_opts=opts.AxisOpts( name="数量", type_="value", min_=0, max_=1500, # interval=50, axislabel_opts=opts.LabelOpts(formatter="{value}"), axistick_opts=opts.AxisTickOpts(is_show=True), splitline_opts=opts.SplitLineOpts(is_show=True), ), ) ) # 画出平均薪资的折线 line = ( Line() .add_xaxis(xaxis_data=city_nums[:10].index.tolist()) .add_yaxis( series_name="平均薪资", yaxis_index=1, y_axis=city_salary, label_opts=opts.LabelOpts(is_show=False), ) ) # 当这个程序有可能被导入时,写这个判断 # 直接用python程序调用当前这个脚本时,__name__为__main__,执行下面 # 当这个程序被导入时,__name__不为__main__,便不会执行 if __name__ == '__main__': # 生成页面,表示柱状图里面套着线图 p3obj.overlap(line).render("3.各城市招聘量柱状图及平均薪资折线图组合.html")生成网页 3.各城市招聘量柱状图及平均薪资折线图组合.html p4.py from pyecharts.charts import HeatMap from pyecharts import options as opts ''' 4. 各城市岗位薪资分布热力图 ''' # 1 读取数据 # 从publicFunction中导入read_works函数 from publicFunction import read_works # 调用此函数,完成数据的读取和处理 data_cy = read_works() # 2 统计数据 # 生成城市为行索引,工作类别为列索引,薪资为表格值的透视表。 city_data = data_cy.pivot_table(index=['城市'], columns=['岗位类别'], aggfunc={'最高薪资': 'mean'}) # 按‘python’列对透视表进行降序排列,ascending 升序 city_data.sort_values([('最高薪资', 'python')], ascending=False, inplace=True, na_position='last') # print(city_data) # 取前20个最高薪资 top_city = city_data[:20]['最高薪资'] # print(top_city) # 做成数据透视表进行绘图 values = [[item_col, item_index, round(top_city.iloc[item_index, item_col], 2)] for item_col in range(len(top_city.columns)) for item_index in range(len(top_city.index))] # print(top_city.index.tolist())#行名 # print(top_city.columns.tolist())#列名 # print(values)#[行坐标,列坐标,薪资] # 3 绘图 # InitOpts(width="1200px", height="800px")设置图的宽高 p4obj = HeatMap(init_opts=opts.InitOpts(width="1200px", height="800px")) p4obj.add_xaxis(top_city.columns.tolist()) p4obj.add_yaxis("平均最高薪资", top_city.index.tolist(), values,label_opts=opts.LabelOpts(is_show=True, position="inside"),) p4obj.set_global_opts( title_opts=opts.TitleOpts(title="各城市岗位薪资分布热力图"), visualmap_opts=opts.VisualMapOpts(min_=5000, max_=50000), xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)) ) # 当这个程序有可能被导入时,写这个判断 # 直接用python程序调用当前这个脚本时,__name__为__main__,执行下面 # 当这个程序被导入时,__name__不为__main__,便不会执行 if __name__ == '__main__': p4obj.render("4.各城市岗位薪资分布热力图.html")生成网页 4.各城市岗位薪资分布热力图.html p5.py from pyecharts.charts import Bar,WordCloud,Page from pyecharts import options as opts import re import collections import jieba ''' 5. 数据科学工具要求排行柱状图和岗位技能要求词云 ''' # 1 读取数据 # 从publicFunction中导入read_works函数和word_count函数 from publicFunction import read_works,word_count # 调用此函数,完成数据的读取和处理 data_cy = read_works() # 只拿出数据科学的岗位进行分析 data_cy = data_cy[data_cy['岗位类别'] == '数据科学'].copy() # 2 拼接所有岗位描述 string_data = '' for i in data_cy['岗位描述']: string_data += str(i) # 从大字符串中取出所有英文单词 list1 = re.findall('[a-zA-Z]+', string_data, flags=re.S) # 把所有取出的英文单词转换成大写 list2 = [item1.upper() for item1 in list1] # print(list2) word_counts = collections.Counter(list2) # 对分词做词频统计 word_counts_top = word_counts.most_common(10) # 获取前10最高频的词 # 绘出数据分析所需工具排行最高的柱状图 p5obj1 = Bar() p5obj1.add_xaxis([i[0] for i in word_counts_top]) p5obj1.add_yaxis("数据分析工具", [i[1] for i in word_counts_top], color='#CD1076') p5obj1.set_global_opts( title_opts=opts.TitleOpts(title="数据分析工具排行"), xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)) ) # 绘制岗位要求词云图 # 调用word_count函数,进行文本处理,并提取词频排行前100的词 word_counts = word_count(string_data) # 绘制词云 p5obj2 = WordCloud() p5obj2.add( series_name="岗位技能要求", data_pair=word_counts, word_size_range=[20, 80], ) p5obj2.set_global_opts( title_opts=opts.TitleOpts(title="岗位技能要求"), tooltip_opts=opts.TooltipOpts(is_show=True), ) # 当这个程序有可能被导入时,写这个判断 # 直接用python程序调用当前这个脚本时,__name__为__main__,执行下面 # 当这个程序被导入时,__name__不为__main__,便不会执行 if __name__ == '__main__': page = Page() page.add(p5obj2,p5obj1) page.render('5.数据科学工具要求排行柱状图和岗位技能要求词云.html')生成网页 5.数据科学工具要求排行柱状图和岗位技能要求词云.html p6.py from pyecharts.charts import Bar,Page from pyecharts import options as opts ''' 6.不同岗位对学历和工作经验要求分布柱状图 ''' # 读取数据 # 从publicFunction中导入read_works函数 from publicFunction import read_works # 调用此函数,完成数据的读取和处理 data_cy = read_works() # 不同岗位对学历要求分布柱状图 # 统计学历要求数据 # 按照岗位类别、学历要求分组来统计数量,根据岗位id来计数 data_gr = data_cy.groupby(['岗位类别', '学历要求']).count()['岗位id'] # 计算各种学历在每个岗位类别中所对应的岗位数量 # print(data_gr) xindex = ['不限','大专','本科','硕士','博士'] # 选取工作类别‘java’、‘python’、‘数据科学’、‘算法工程师’所对应的数据,画出不同岗位对学历要求分布柱状图 p6obj1 = Bar() p6obj1.add_xaxis(xindex) p6obj1.add_yaxis("java", list(data_gr['java'].reindex(xindex)), gap="0%") p6obj1.add_yaxis("python", list(data_gr['python'].reindex(xindex)), gap="0%") p6obj1.add_yaxis("数据科学", list(data_gr['数据科学'].reindex(xindex)), gap="0%") p6obj1.add_yaxis("算法工程师", list(data_gr['算法工程师'].reindex(xindex)), gap="0%") p6obj1.set_global_opts(title_opts=opts.TitleOpts(title="不同岗位对学历要求分布柱状图")) # 不同岗位对工作经验要求分布柱状图 # 统计对应工作经验数据 # 按照岗位类别、工作年限分组来统计数量,根据岗位id来计数 data_gr1 = data_cy.groupby(['岗位类别', '工作年限']).count()['岗位id'] # 计算每个岗位类别中相同工作年限的要求的数量 # print(data_gr1) yindex = ['不限','在校/应届','1年以下','1-3年','3-5年','5-10年','10年以上'] # 选取工作类别‘java’、‘python’、‘数据科学’、‘算法工程师’所对应的数据,画出不同岗位对工作经验要求分布柱状图 p6obj2 = Bar() p6obj2.add_xaxis(yindex) p6obj2.add_yaxis("java", list(data_gr1['java'].reindex(yindex)), gap="0%") p6obj2.add_yaxis("python", list(data_gr1['python'].reindex(yindex)), gap="0%") p6obj2.add_yaxis("数据科学", list(data_gr1['数据科学'].reindex(yindex)), gap="0%") p6obj2.add_yaxis("算法工程师", list(data_gr1['算法工程师'].reindex(yindex)), gap="0%") p6obj2.set_global_opts(title_opts=opts.TitleOpts(title="不同岗位对经验要求分布柱状图")) # 当这个程序有可能被导入时,写这个判断 # 直接用python程序调用当前这个脚本时,__name__为__main__,执行下面 # 当这个程序被导入时,__name__不为__main__,便不会执行 if __name__ == '__main__': page = Page(layout=Page.SimplePageLayout) page.add(p6obj1,p6obj2) TT = page.render("6.不同岗位对学历和工作经验要求分布柱状图.html")生成网页 6.不同岗位对学历和工作经验要求分布柱状图.html combine.py # 将其他文件导入 import p1,p2,p3,p4,p5,p6 ''' 此时p1,p2,p3,p4,p5,p6文件中的if __name__ == '__main__':语句就发挥了作用 此时为被导入的情况,p1,p2,p3,p4,p5,p6中的__name__ 就不为 '__main__',便不会在原来的文件中再生成页面 ''' from pyecharts.charts import Tab # 选项卡页面 tab = Tab() # 把每一个做成一个选项卡,放入其中 tab.add(p1.p1obj,'各岗位占比饼图') tab.add(p2.p2obj,'各岗位平均起薪柱状图') tab.add(p3.p3obj.overlap(p3.line),'各城市招聘量柱状图及平均薪资折线图组合') tab.add(p4.p4obj,'各城市岗位薪资分布热力图') tab.add(p5.p5obj2,'数据科学岗位技能要求词云') tab.add(p5.p5obj1,'数据科学工具要求排行柱状图') tab.add(p6.p6obj1,'不同岗位对学历要求分布柱状图') tab.add(p6.p6obj2,'不同岗位对工作经验要求分布柱状图') # 生成页面 tab.render("combine.html")生成网页 combine.html 若运行时报此错误: GitHub链接:Python-PyechartsVis |
 过滤词表(只在p5.py绘制词云中用到) remove_words.txt
过滤词表(只在p5.py绘制词云中用到) remove_words.txt 






 点击上面的选项卡会展现相应的图表
点击上面的选项卡会展现相应的图表 是pyecharts版本的原因 只需用以下命令重新安装即可
是pyecharts版本的原因 只需用以下命令重新安装即可【本文地址】